Locality of reference, which is sometimes known as the principle of locality, is a term to describe the phenomenon in which the same part of a program or data set is frequently accessed. For example, when you use a program like a web browser, you’re generally using it to visit websites and render (display) web pages. However, browsers are capable of all sorts of other things, such as debugging pages, interpreting Java programs or scripts and even running apps right there in the browser, but most of us don’t need all this functionality, certainly not all the time. The locality of reference for the web browser would suggest that most of the time (and yes, that’s nice and vague, but that’s okay for us for now) the code that really matters is the code for browsing.
Why is this important to us? As designers of fast and efficient programs, we need to be aware of the limitations of the hardware we’re working with. Consider the image below:
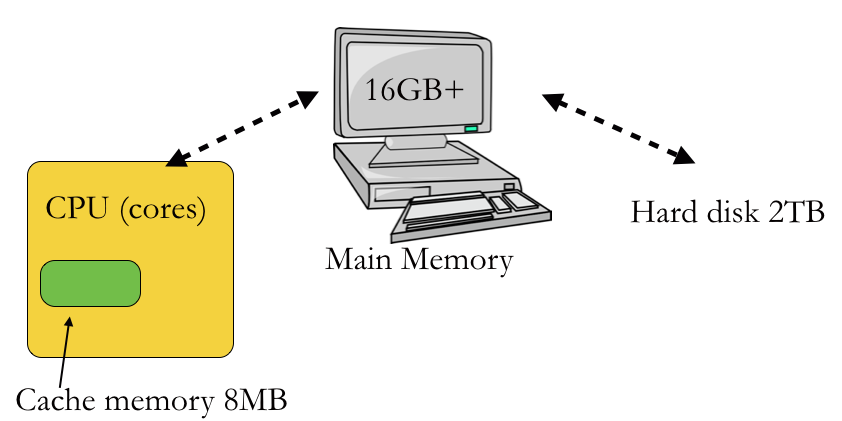
Different memory/storage types in modern computers. Cache memory is small but several orders of magnitude faster than disks.
When running, our programs (or at least parts of them) sit in the main memory of the computer which often has a generous amount of memory, but when we actually execute the instructions, they are moved into the Central Processing Unit (CPU) or the processing cores. The cores have a very small amount of super fast memory called cache memory. It takes approximately 0.25 nanoseconds to access data in the cache compared to 60 nanoseconds from main memory. That’s a whopping 240 times faster! By comparison, it takes about 7 microseconds to get data from a standard hard disk – a microsecond is a thousand times longer than a nanosecond.
If we want our programs to run fast, we want to make sure that the key parts of them fit in the cache, so we want to make them as small and efficient as possible, because they run so much faster when we don’t a cache miss, that is, when we never have to go back to the computer and ask for more data. In fact, the CPU runs so much faster when it doesn’t have to access main memory that it is often faster to do the same things many times than it is to do one more complex thing once. This is a bit counter-intuitive, but we’ll see this coming up again and again: we would rather design programs that do something very simple many times than ones that do some crazily complicated once.
Lots of modern hardware suits this sort of design. Internet of Things (IoT) devices have really simple processors, so the code has to be super efficient, Edge Computing, where the processing happens in small devices like phones or sensors, is only possible if we have the magic combination of useful hardware and excellent software – that’s where we come in!
As we move forward, we’ll try to do both of these whenever possible:
- Minimize the memory footprint (keep the program small)
- Reuse functionality (do the same thing over and over if possible)
With these in mind, let’s get back to expressions and see if we can make processing them easier.